Dane syntetyczne w badaniach marketingowych

Dane syntetyczne w badaniach marketingowych? No, to jest temat! A teraz wyobraź sobie: zamiast przez miesiące ganiać za respondentami, wysyłać ankiety, dzwonić do tych biednych ludzi w niedzielę rano, wszystko załatwiasz w kilka minut. Jak? Oczywiście, pytasz LLMa! Tak, ten sam chatbot, co właśnie pomaga ci pisać maile z wymówkami do szefa :)
No dobra, to był taki wstęp “do śmichu”, a teraz na poważnie:
Co by się stało, gdybyśmy zadali ChatGPT to samo pytanie 385 razy? Odpowiedź jest prosta: otrzymalibyśmy pełnoprawne badanie marketingowe. I to nie byle jakie—wyniki byłyby zaskakująco zbliżone do tych uzyskanych od żywych respondentów, ale proces byłby znacznie szybszy i tańszy.
Nie jestem w tym odosobniony. Badania przeprowadzone przez uniwersytety takie jak Berkeley i Harvard Business School potwierdzają tę tendencję. Firmy badawcze jak Kantar i organizacje branżowe jak ESOMAR bacznie się temu przyglądają. Sam przeprowadziłem własne eksperymenty i uzyskałem podobne wyniki.
W niektórych przypadkach wyniki syntetyczne pokrywają się z rzeczywistymi na poziomie 80-90%. To na tyle obiecujące, że pomyślałem, że za chwilę będzie z tego biznes. I widać nie pomyślałem tak tylko ja, bo niedawno Jon Lombardo, były szef B2B Institute z LinkedIn, otworzył firmę zajmującą się właśnie tym i już korzystają z niej takie marki jak Mars czy EY.
Czym są dane syntetyczne?
Dane syntetyczne różnią się od tradycyjnych tym, że zamiast zadawać pytania żywym ludziom, kierujemy je do modeli językowych, takich jak ChatGPT. Proces jest nieco inny niż zwykła interakcja z chatbotem. Za pośrednictwem API wysyłamy setki zapytań (to samo pytanie wielokrotnie), albo pytania z modyfikowanymi parametrami syntetycznego respondenta.
Co ważne, pytania są formułowane w sposób zbliżony do ankiet, gdzie model może wybierać spośród dostępnych opcji. Wyglądać to może na przykład tak:


Praktyczne zastosowanie
Przykładowo, badano “willingness to pay” za określone cechy produktu—co normalnie wymagałoby zastosowania conjointów. Wyniki? Różnie, raz lepiej raz gorzej, na pewno da się je poprawić. Wychodziło średnio 60-70% zgodności z danymi uzyskanymi od ludzkich respondentów. Oczywiście, w przypadku bardziej nowatorskich produktów czy nietypowych segmentów klientów zgodność spadała poniżej 50%.
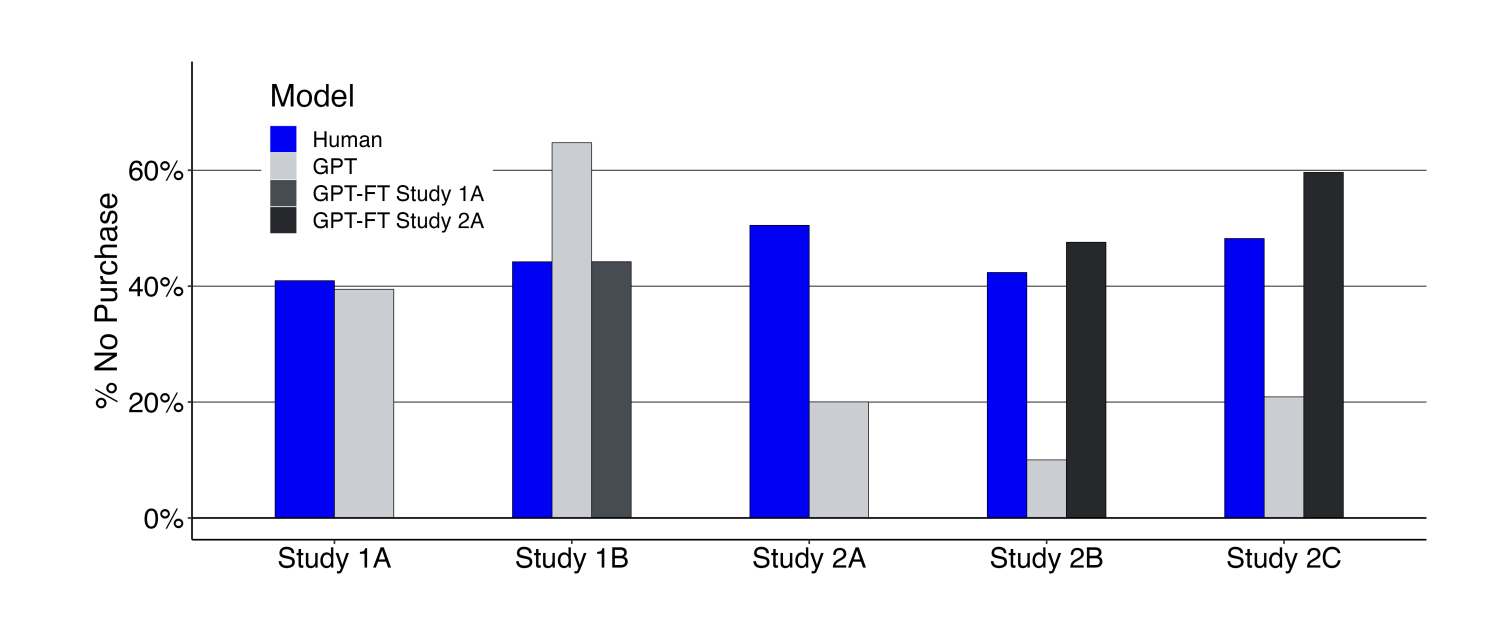
Podobne rezultaty uzyskano przy tworzeniu map percepcji marki, gdzie zgodność wyniosła około 80%.
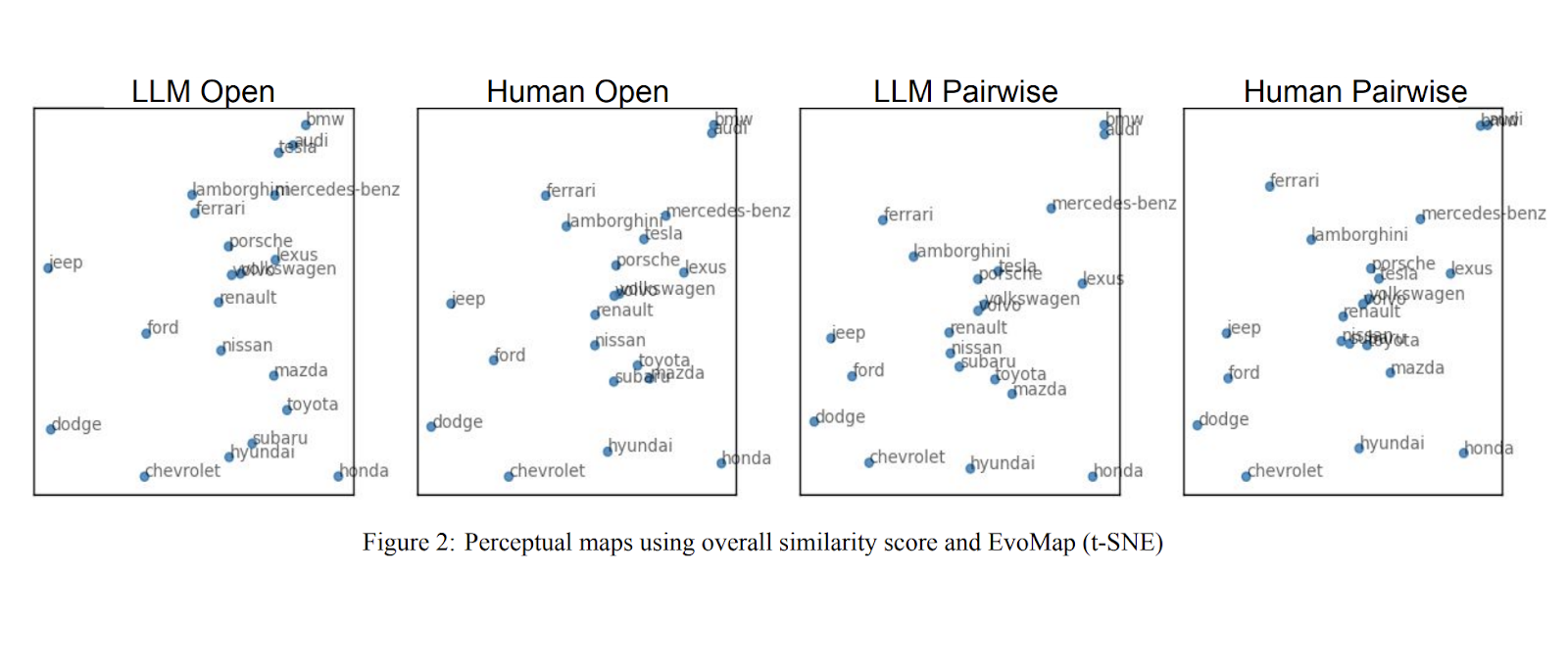
Moje doświadczenia
Postanowiłem przeprowadzić własny test. Wybrałem dostępne w internecie badanie z udostępnionymi pytaniami dla respondentów. Uzyskałem dostęp do API OpenAI, wydałem dosłownie kilka dolarów i w ciągu kilkunastu minut miałem gotowy kod. Po kolejnych dwóch minutach dysponowałem wynikami mojego syntetycznego badania. Rezultat? Odpowiedzi były niezwykle zbliżone do oryginalnych
Wyzwania i ograniczenia
Oczywiście, takie podejście ma swoje wady:
-
Wrażliwość na sformułowanie promptu: Małe zmiany w pytaniu mogą znacząco wpłynąć na odpowiedzi.
-
Nadmierny optymizm modelu: Sztuczna inteligencja może przejawiać tendencję do zbyt pozytywnych odpowiedzi.
-
Wrażliwość na kolejność opcji: Kolejność prezentowanych odpowiedzi może wpływać na wybór modelu.
-
Braki w danych treningowych: Modele mogą nie posiadać informacji na temat najnowszych trendów czy danych specyficznych dla niszowych rynków.
-
Aktualność danych: Modele opierają się na danych sprzed pewnego czasu, co może wpływać na ich zdolność do odzwierciedlania bieżących realiów rynkowych.
Co przyniesie przyszłość?
To nie jest już przyszłość—to teraźniejszość. Możemy spodziewać się, że w niedługim czasie będzie to działało tak - 10% żywych panelistów, a reszta zostanie uzupełniona przez syntetycznych respondentów. Jedno jest pewne: dane syntetyczne w badaniach marketingowych to trend, którego nie można ignorować. Czy zastąpią one całkowicie tradycyjne metody? Wątpię. Ale jako narzędzie komplementarne mają potencjał zrewolucjonizować sposób, w jaki pozyskujemy i analizujemy dane, szczególnie tam gdzie jest to trudne.
Źródła:
-
Peiyao Li, Noah Castelo, Zsolt Katona, and Miklos Sarvary: Language Models for Automated Market Research: A New Way to Generate Perceptual Maps
-
Working Paper 23-062 Using LLMs for Market Research James Brand Ayelet Israeli Donald Ngwe